
There's a new way people are making software at the frontier. In those fancy startups tucked away in san francisco, or behind the 4 levels of security at the labs, or the guy on his laptop at the $9 per-cup williamsburg cafe.
It's called agent native engineering, and it's what actually separates the 1x from the 100x engineers. You'll see people posting about their 12 claude code terminals they have running at once, but is that actually feasible? How does it all actually work? What even is agent native engineering?
Put simply, agent native engineering means restructuring your organization around agents as individual-contributors instead of engineers. Let's discuss what that actually means.
Background agents changed everything
The shift started with Devin from Cognition AI. In summer 2024, it was the first asyncronous coding agent. That means you could assign it a task, walk away, and come back to new code committed to your codebase in a PR. An agent that could run in the background and not be managed directly.
Summer 2024 was early for agents - Devin sucked. But the models got better and so did Devin. Basically every startup I know used Devin in 2025. Something I realized, though, was that Devin itself isn't actually a good coding agent. We used it internally at General Intelligence, and churned in October.
What mattered wasn't Devin 's coding performance. It was the pattern of work that Devin enabled. Engineers could now operate two parallel work streams. They could work on their task directly in an IDE, and assign lower level tasks to a background agent.
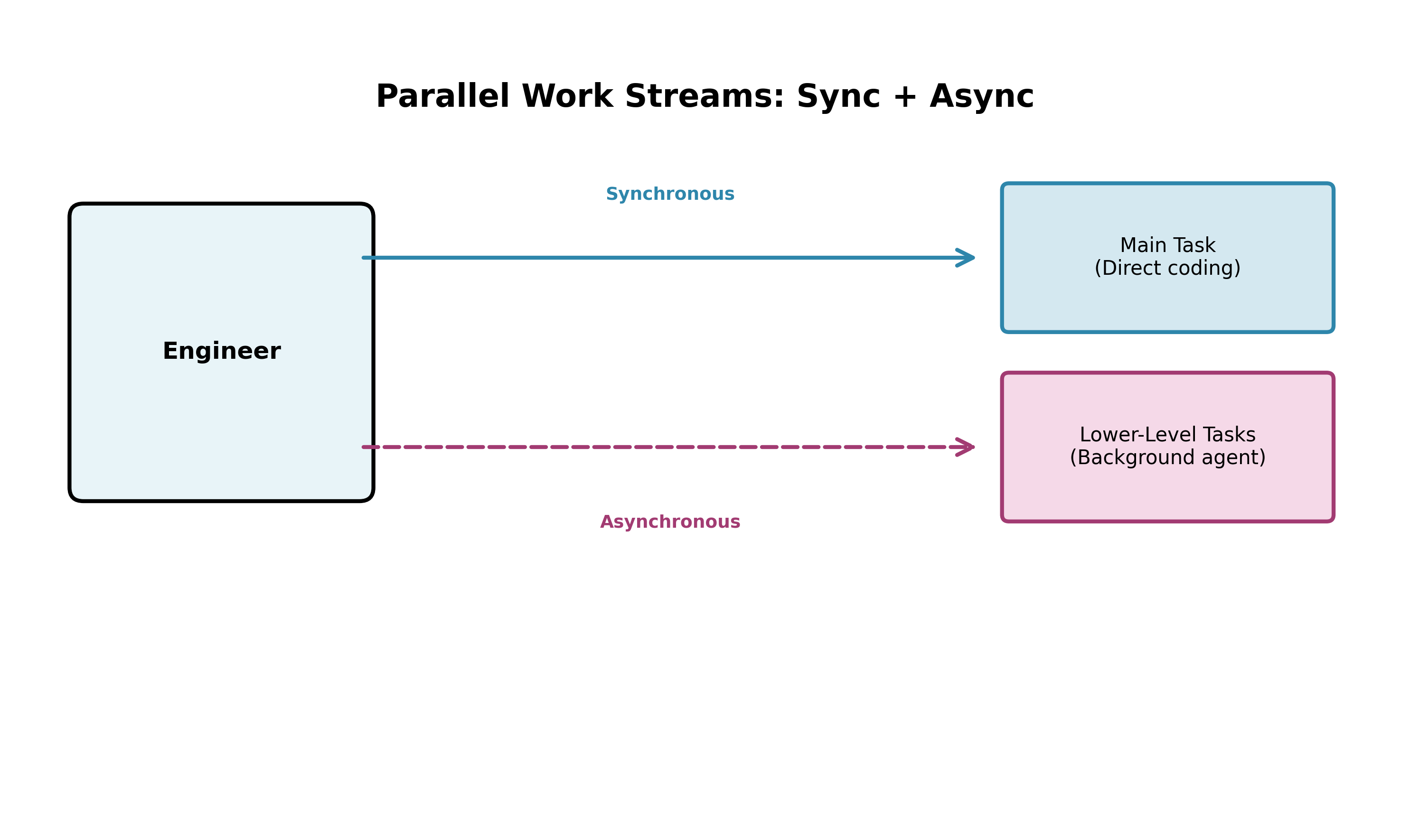
This reduces downtime pretty significantly, and allows a higher level of a polish for output. You can iterate faster by getting V1 of something out synchrounously, then addressing small bug fixes and issues afterwards by delegating an async agent.
How do background agents actually work?
Background agents require a few things:
- A sandbox they can work in to write and run code.
- Access to github to push code via PRs.
- A coding agent itself, hosted somewhere to run asyncronously.
- The ability to iterate on feedback, either github comments or via slack/chat
Devin was the first to contain all of these, but now there's a ton around like Tembo, Factory, Cursor Cloud Agents, and Claude Code in a sandbox. And now, Linear integrates with all of these - so users can spin them up directly via Linear tickets. Now, a fairly-sophisticated-yet-highly-efficient workflow has emerged for background agents.
Background agents engineering workflow
- Someone has a new feature idea that is scoped narrow enough
- A linear ticket is created for the feature
- The linear ticket is assigned to a person and coding agent, because someone still has to be responsible for the ticket.
- A coding agent works on the ticket in the background and eventually makes a pull request
- The coding agent iterates on CI/tests until they pass and checks for merge conflicts
- The engineer assigned reviews the code, sometimes running the branch locally
- [optional] The engineer assigned leaves comments on the PR or linear ticket
- The coding agent automatically addresses feedback and makes new commits
- The engineer approves and merges the code.
This leaves the engineer time to do other things, much like a PM assigning work might do. Work must still be reviewed, but the load of working synchronously is taken off.
Giving your engineers coding agents is not agent native engineering.
Agent native engineering is a system for managing a team around this workflow of sync+async work. It has a few effects on the way a team works. You can only call your department agent-native if it is built around agents and not people.
So how do you do that?
You must start thinking of tasks in three levels, depending on how they can be worked on by agents:
- Simple (aka one-shottable): A well written prompt for a task will get coded by an agent and merged easily. This is usually for small things like "change the corner radius on this button."
- Easily manageable: A background agent with some feedback cycles can solve the task and get the code merged.
- Complex: A task managed directly by an engineer using synchronous coding agents. Full flow, design intensive, or something similar.
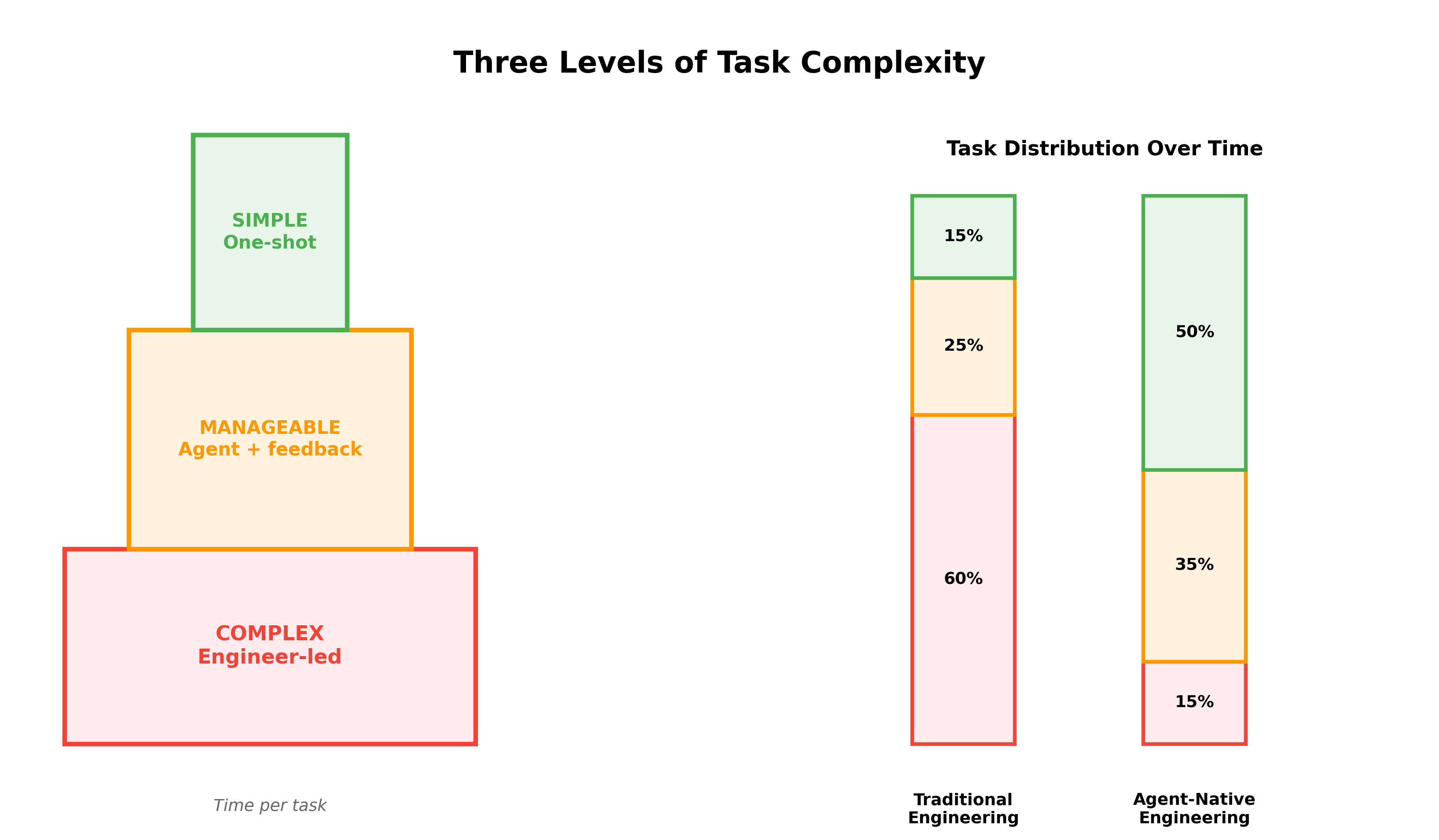
Every task except complex should be delegated. Agents become the primary ICs in your organization - managed by engineers. Given this pattern, simple tasks are done almost instantly, manageable tasks are done daily, and complex tasks are where engineers spend most of their time.
Complex tasks are still completed quickly given the strength of these models. Its become unlikely someone works on the same task for more than one day, and almost unacceptable if someone works on the same thing for more than one week.
Even the most complex tasks are just torn through by these models. It's totally changed from just six months ago.
With this, your managers become staff engineers and your engineers become tech leads. And over time, the % of tasks that are simple and manageable goes up while the % of tasks that are complex goes down.
The time an engineer spends synchronously coding is inversely correlated to the time horizon of agentic coding models; so as the models improve on long horizon tasks, your engineers will be spending less time focusing on writing code.
Agency goes up (lol)
Now that everyone's leveled up, you've got to give them more agency. Give engineers larger features with less specs and let them figure the rest out with their new team. Give managers larger objectives. Stop requiring a second engineer to review every PR.
If people on your team can't rip features as quickly as they can come up with them, something you are doing is slowing them down.
You should remove the two engineer code review requirement
A two engineer code review totally ruins this dynamic. If your engineer is able to manage five simple tasks, two manageable tasks, and one complex task at a time, your two engineer code review system now requires them to review ten simple tasks (theirs and others), four manageable tasks, and two complex tasks. This will be the hardest thing to adapt to if you run an established engineering org.
If you're managing an engineering org, one of your jobs is to streamline this process. Some ideas are: Take advantage of agentic pentesting companies, add code review agents like cursor bugbot or greptile, add an AI SRE to your staging environment. But do everything in your power to remove the two engineer code review requirement.
"but security" "but code reviews" you are thinking in the way of the past. In this new world you will live and die by the number of iterations you can complete in a given amount of time. You need to restructure your engineering org so the impacts of every new model release are felt. Otherwise, people like me will outship you.
Think about it from your engineer's perspective. An engineer that can rip dozens of PRs a day and tokyo drift 12 instances of claude code will build and iterate on a product very quickly, and if you prevent them from doing that they'll go somewhere that won't.*
*we're hiring btw - generalintelligencecompany.com/careers
What about code slop?
Code slop is very real, but it's preventable by having robust rulesets and tests. You can create claude.md files or .cursorrules (or whatever standard) to enforce style and quality. Running an effective agent native engineering org means spending time on your rulesets. Internally, we have different rules for our frontend codebase, backend, overall architecture, code style guidelines, and component style guidelines.
Agents are good at reading rules. They have been RL'd to read them and utilize them well. They have not been trained to write them very well (yet) - so this largely falls on engineers and managers to be able to buildout a rules function at an engineering org.
Tests are also quite important. Your agents need a reward signal - something that tells them if the stuff they did worked or not. Tests are this reward signal. If the right tests are implemented and passing them is required before a merge, the agent will iterate until the tests pass.
We also make use of linters such as eslint and style formatters such as python black. This contributes to consistent styling and significantly improves low-level slop.
Combining intelligent rulesets with a robust set of tests and linters significantly reduces code slop. And with models improving every few months, code slop will be further improved on its own at each iteration.
Finally, code review bots have gotten very very good. We use Cursor's Bugbot. It catches bugs at a really high rate, and contributes to better codebase quality overall.
How agent native engineering effects an org
As async coding agents improve, engineering teams see themselves managing more and coding less. The time it takes an engineer to complete any given task is continues to go down significantly. The time it takes to decompose larger tasks into smaller ones is also continues to go down significantly.
As a result, the time spent managing a ticketing system becomes a larger % of your workflow. Reviewing code becomes a much larger % of your workflow. People spend time thinking about what to do and less time thinking about how to do it. In effect, everyone's a PM and team lead for whatever project they're working on.
Your product will also change rapidly. It becomes much more of a moving target to plan a roadmap, and makes roadmaps longer than a few weeks ineffective. Running an agent native engineering org feels way more like real time strategy than turn based (as it was before).
Tight collaboration cycles become very important, and you live and die by actions-per-minute. This is why I prefer in-office every day as a policy - it lowers friction of ideas and increases the rate at which new ideas are generated.
Speaking of idea generation, that's the new problem. Before 2026 engineers had to spend time using their high level of intelligence solving relatively narrow well defined problems. Now, most of those problems are simple or manageable by background agents. Your engineers' new job is to find more problems to solve. That's why many are saying its the golden age of the idea guy - it is. If you can narrowly scope a problem then hand it off to an engineer, you might as well just hand it off to a background agent.
You probably need more designers and product people
Since everyone's spending more time on ideas, those ideas have to be translated into usable (and beautiful) product. Engineers are OK at this. They can make the best performing amazing system ever and in their mind it will be functional. Your users may disagree. Often it will be functional, but it'll feel clunky and look like shit. This is not the engineer's fault - they were probably solving leetcode problems a year ago to get a job writing unit tests at google (and they were really good at it).
The truth is engineers ripping PRs need design support by either PMs or designers. Ideally, both. And most orgs actually have this function pretty well, having a solid ratio of designers to engineers. And engineering typically lags design, since the complexity of developing a product is much higher than designing the product. This is still true, but with agent native the ratio is changing. If your ratio was 1:20 like is fairly common at these orgs, its now too low. You need more people who can reason about experience, product, and design than you did before because new features will materialize at the speed of thought.
This is something we learned at general intelligence. We sped up our engineering significantly in December, and in January we fell way behind on design/UX because of it.
Be not afraid of your engineer's token spend
We don't cap our engineer's token spend. No - i mean we literally don't. Not at all. In January 2026*, we spent an average of $4000 per engineer per month on opus tokens. That is an enormous amount of money to be spending on tokens.**
Why? At 4k, that's a solid % of that engineer's total salary. This is kinda crazy. Yes. However, in January 2026 our engineers also shipped an average of 20 PRs a day, sometimes hundreds of commits daily. We are spending roughly 20% more on engineering intelligence to increase output by a factor of 3-4x. That's an incredible tradeoff. I estimate our token spend as a % of our engineering budget will continue to climb into the year until we hit some plateau that involves how quickly we can turn the spend into revenue, but there's no reason we wouldn't go over 100%.
*as of January 28th when im writing this
Final mysterious thing that i cant tell you about
The most impactful thing you can do is one i'm actually going to leave out of this article. We'll announce this the first week of march and are opening the alpha in two weeks. Please sign up here to join the alpha!
The future of agent-native engineering
To summarize, the state of play is the following:
- Synchronous agents for complex work
- Delegation to async agents for manageable and simple tasks.
- Code review bots and task management systems
What's going to change is that IDEs as we know them will go away. Code review by humans will go away. By the end of 2026, humans will review only changes on products and larger infrastructure - in effect making all engineers product managers and all product managers engineers.
The future looks like:
- Highly capable background agents like teams, with everything delegated first.
- Advanced plan mode UIs, akin to PRDs of the past, for complex feature sets.
- Beautiful (non-artistic) frontend code largely automated, including animation, making functional beautiful UI at a few keystrokes.
- All infrastructure becomes code and anything that isnt infra-as-code begins to go away.
- Teams become smaller and more capable.
- Designers or those that can design matter more, while engineers who are not product thinkers matter less.
Every organization must become agent native, or they will cease to exist. Luckily, that means more efficient and productive companies. If this scares you, you're in the wrong place for the future.
-Andrew Pignanelli
Cofounder and CEO, The General Intelligence Company Of New York
