
It is often said that life is shaped by the actions we repeat. Our habits form our bodies, our environment, and ultimately the lives we create.
Running a company works the same way. As a CEO, your days are filled with recurring actions that, over time, shape the identity and performance of the business. For example, you might (ranging from simple to highly complex):
- Draft standup points for your team to keep everyone aligned.
- Prepare updates for investors by pulling analytics from every corner of the business.
- Design, test, and evaluate new marketing campaigns based on opposition research to better understand competitors and market trends.
Individually, these tasks may feel small. But done repeatedly, they become the backbone of the company and the routines that drive culture, decision-making, and execution. At any given moment, any company could be decomposed into these repeatable flows of work. They may be complex, but they are repeatable; otherwise, performance would never be reproducible.
This is the philosophy behind Cofounder and its automation system called Flows. Flows let you create powerful workflows that run automatically, triggered by events, schedules, or manual execution. From simple building blocks, complex organizational behavior emerges.
But meaningful flows aren't just one-off tasks. They span multiple integrations, decision points, and time horizons. A truly useful flow remembers not only the message you received an hour ago but also the one you got a month ago. That's why state-of-the-art agents require state-of-the-art memory — memory designed for long horizons, across weeks and months, not just a single session.
In our last blog post, we argued that memory is the final step on the road to AGI. We aren't claiming AGI today, but we do believe Cofounder represents a step forward in agent memory. Without robust memory, agents are unable to accumulate knowledge across interactions, leading to brittle behaviors, repeated mistakes, and limited long-horizon reasoning. Here at GIC, we equip Cofounder with layered memory systems that consolidate, abstract, and persist information over time. With Cofounder, we are capable of agents that can adapt, personalize, and collaborate over extended horizons.
Just as in Conway's Game of Life, where a seemingly random arrangement of pixels blossoms into complex, recurring patterns, Cofounder's memory arises from a set of carefully designed, curated operations happening all in the background.

Conway's Game of Life seeded with the Cofounder logo as the initial condition.
The Three-Tier Memory System
To this end, we introduce a three-tier memory system: working memory, core memory, and long-term memory.
Working Memory
Working memory functions as the active workspace for the agent, persisting within a session to store conversational history, tool outputs, and intermediate reasoning steps.
Core Memory
Core memory serves as personalized short-term memory, consolidating recent sessions into compact knowledge representations and capturing user-specific preferences, all in a dialogue style. We note that our short-term memory is often retrieved based on a call-and-answer format (e.g., What is my mom's favorite bagel at the bodega down the street? Oh, it's a lox on an everything bagel). More importantly, this short-term, conversation-like memory captures how Cofounder previously used memory for similar tasks.
Long-Term Memory
Long-term memory persists durable, organizationally critical knowledge (e.g. team structure, project roadmaps, long-horizon objectives) integrated via enterprise tools such as Gmail, Notion, Linear, and Slack. It creates the foundation of a broader knowledge base, with a shared ontology that persists throughout the lifecycle of the user.
Together, these three layers work to avoid their individual pitfalls: immediate reasoning and work in progress at the expense of persistence; episodic recall at the expense of intricate structure; and structured, long-term memory at the expense of the agility of short-term memory.
Sleep-Time Compute for Memory Consolidation
To decide what should be consolidated into short-term versus long-term memory, we draw inspiration from the process of memory consolidation during sleep. Specifically, we leverage "sleep-time compute", which performs background inference to reorganize stored information between interactions. This allows agents to pre-compute abstractions, reduce test-time latency, and amortize computation across queries.
Evaluating Memory: Beyond Long Context
Evaluating such architectures presents a challenge. Unlike well-established measures of accuracy for reasoning or mathematical tasks, there is no single metric that captures all aspects of memory. Previous benchmarks have focused largely on long-context processing, which test whether models can attend over long sequences (e.g., LOCOMO across ∼9k tokens, LooGLE across ∼24k tokens, and ∞-Bench across ∼150k tokens).
However, long context and memory are not equivalent. Long-context methods recite prior inputs verbatim, whereas memory systems compress, distill, and reorganize information incrementally. Human memory does not consist of exact transcripts of past experiences but rather selective abstractions and generalizations that enable reasoning in new settings.
To address this gap, we use MemoryAgentBench, a benchmark from July of this year explicitly designed to evaluate agents that must consolidate, recall, and adapt information over time. Unlike long-context datasets, MemoryAgentBench evaluates the decision process behind what information should be emphasized or discarded; what should be recalled or learned; and what should be updated or persisted—all core to how Cofounder works.
Four Dimensions of Memory
MemoryAgentBench introduces four different aspects of memory:
- Accurate Retrieval — the ability to locate dispersed facts across a long context, akin to Needle-in-a-Haystack tasks
- Test-Time Learning — the ability to acquire new skills dynamically during deployment, analogous to in-context learning but through a history of dialogue
- Long-Range Understanding — the capacity to integrate knowledge across longer horizons
- Conflict Resolution — the ability to update or overwrite previously stored knowledge when facts change
These dimensions reflect the requirements for memory agents operating in real-world organizational contexts. Here, today, we report two case studies in Accurate Retrieval and Test-Time Learning.
Benchmarking Results
We benchmark Cofounder against existing memory-centric architectures, including MemGPT, Self-RAG, and retrieval-augmented generation (RAG) baselines such as Mem0. While RAG methods perform well on document-level question answering, they struggle with ambiguous queries, multi-hop reasoning, and tasks that require integrating knowledge distributed across extended interactions. Recent "agentic RAG" variants mitigate some of these shortcomings through iterative retrieval and reasoning, but they remain limited by retrieval bottlenecks and lack durable memory consolidation.
Cofounder advances beyond Self-RAG by not only performing iterative retrieval as needed but also dynamically structuring and reorganizing its own memory prior to retrieval. Unlike MemGPT, Cofounder incorporates a long-term memory solution capable of deciding its own ontologies as new information is ingested to create a knowledge base.
On MemoryAgentBench, Cofounder exhibits multi-step retrieval behavior, issuing an average of 3.2 memory searches per question. Instead of relying on a single recall, it refines evidence across multiple retrieval cycles. To isolate memory capabilities, we evaluate Cofounder in memory-only settings and disable web search and external integrations.
Results Summary
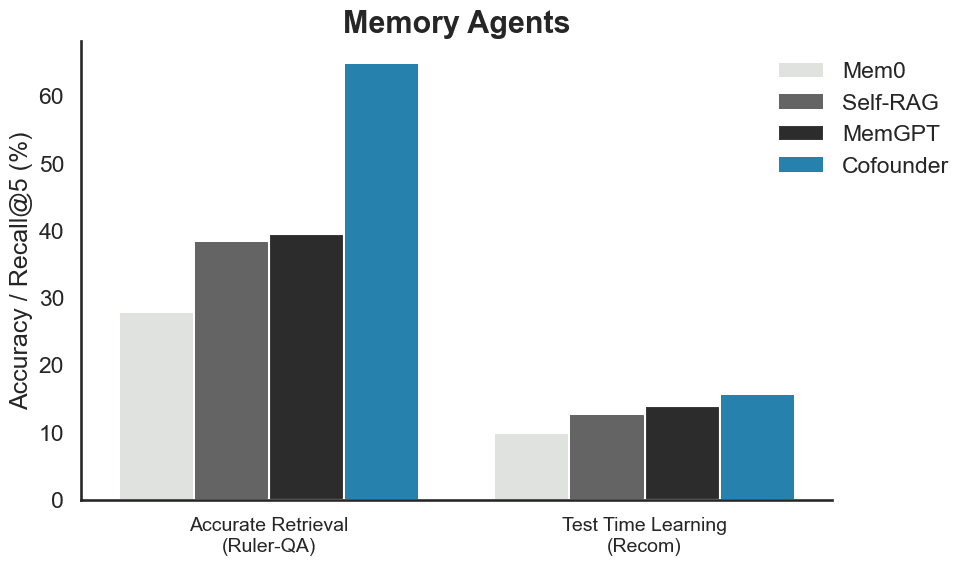

We report results on Ruler-QA, a Needle-in-a-Haystack–style question-answering benchmark in which a long passage contains either a single or multiple snippets relevant to the input query. In addition, we evaluate on ReDial, a dialogue-based movie recommendation dataset. In this evaluation task, the agent is exposed to thousands of movie-related dialogue turns and must recommend n relevant movies based on the entire interaction history. The reported numbers for Mem0, Self-RAG, and MemGPT are taken directly from the MemoryAgentBench paper. We adopt the same memory ingestion prompts and task formulation.
As in MemoryAgentBench, Cofounder is provided chunks of context incrementally (∼309k on average for Ruler-QA; ∼1.4M for ReDial) and then required to locate and extract the correct spans from extended contexts. We compare answers by LLM-as-a-judge (a standard prompt) and accept only those accompanied by a verbalized confidence above 0.95. We adopt retrieval of the top 20 movies, the same as those reported in MemoryAgentBench. Then, we evaluate the recommendations by calculating recall@5, measuring the overlap between the top 5 recommended movies and the ground truth.
More thorough evaluations will follow, but early results suggest we are on the right track. Of course, these benchmarks are not perfect. For instance, one ground-truth label in this dataset expected Jurassic Park (Pinball Machine) when the correct answer should have been the movie Jurassic Park (Cofounder correctly recommended the movie, yet was marked wrong).
What's Next
We still think more needs to be done. While Cofounder outperforms other agentic memory systems in retrieving the appropriate context to answer questions in this benchmark, we acknowledge that there are additional benchmarks where other agents perform well and that we need to evaluate. We also show only marginal improvements in leveraging memory for learning. It is also difficult to benchmark real-world tasks with existing datasets (retrieving a specific feature from Linear, for example). We hope to expand on this soon with improved benchmarks and datasets designed specifically for business use cases.
At The General Intelligence Company, we are pursuing multiple directions: expanding Cofounder memory to better dynamically learn as it interacts with the user, creating new agentic memory benchmarks that incorporate real-world conversations across weeks and months, advancing sleep-time compute for memory consolidation, and exploring memory as the foundation of agent-company culture and personality.
Try Cofounder
Try Cofounder for yourself at cofounder.co, and experience real agentic memory.
